Computer Vision Research

The Summer Undergraduate Research Program is a research fellowship awarded to UCI students who participate in intensive summer research at UCI. I collaborated with another student to develop a research idea and write a proposal (link), which was ultimately selected for funding.
Our research centered around measuring the effectiveness of pseudolabeling, a semi-supervised machine learning technique that we applied to object detection. Object detection is the process of detecting and identifying objects in an image. We take in a raw image from a phone or camera, process it, and output the location of certain objects within the image. Object detection models can be trained to identify various objects such as stop-signs, people, or cars. This technology is used in numerous applications such as self-driving cars, medical imaging, and robotics.


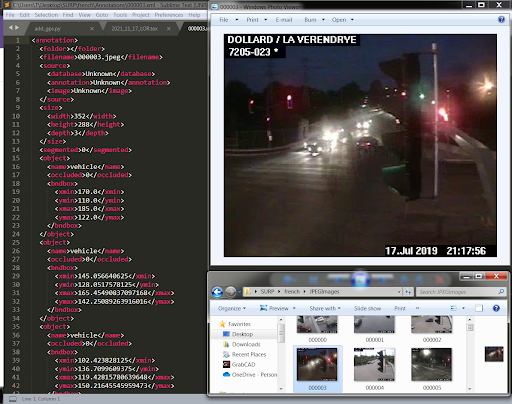
Most object detection methods are reliant on a large training dataset of images labeled and formatted to follow specific conventions. Oftentimes, to achieve high accuracy, thousands of images must be labeled in such a manner. This process can be costly and require entire teams dedicated to labeling. Semi-supervised learning methods attempt to exploit certain features of object detection to reduce the amount of manual labeling required. The figure below shows a standard label file for a single image.
Semi-Supervised Learning
Pseudolabeling is the process of storing object detection model predictions and using those predictions to retrain the model. Pseudolabeling allows the model to learn from data it has never seen before. Unlabeled, raw images are fed into the model, where it makes predictions about object occurrences. We then take the predictions the model is confident about, and treat these instances of detection as additional training data. These additional data are used to retrain the model, increasing its accuracy.
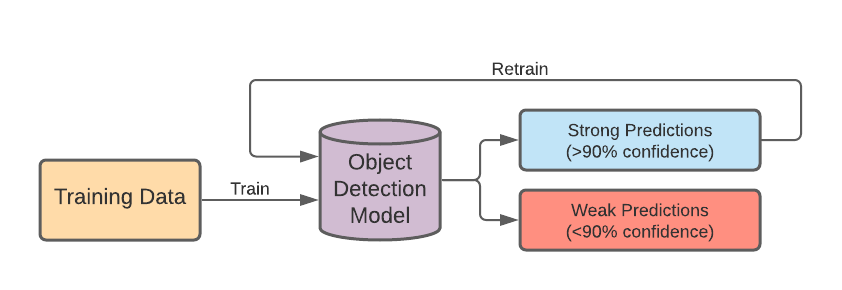
The primary advantage of using this method is that large amounts of unlabeled images can be used to benefit object detection accuracy. Only the initial set of training data has to be labeled, and any subsequent data can be passed through as a raw image (straight from a phone or camera). It is important for this initial set of training data to be sufficiently large to give the model a good baseline, where it can make predictions with a reasonable accuracy.
This technique can be used effectively in situations where large amounts of unlabeled data can be collected. For example, a stationary wildlife camera in the forest or stills from a public video feed. Researchers and programmers that previously did not have access to large amounts of labeled data can use pseudolabeling to increase accessibility to object detection.